In today’s data-driven world, companies are flooded with information but unlocking its true value remains a major hurdle. That’s where Retrieval-Augmented Generation (RAG), especially when paired with Agentic AI, is becoming a game-changer. This powerful combination enables intelligent systems that can search, reason, and respond in real-time turning raw, unstructured data into actionable business insights.
Imagine having an AI agent that can instantly pull relevant data from internal systems, interpret it in context, and deliver clear answers about your products, operations, or integrations without manual digging. That’s the promise of a well-designed RAG pipeline enhanced by agentic behavior.
The momentum behind this technology is undeniable. The global RAG market reached $1.04 billion in 2023 and is projected to grow at a staggering 44.7% CAGR through 2030, fueled by breakthroughs in natural language processing (NLP) and the growing need for context-aware AI.
In this blog, we’ll walk you through how to design a RAG system powered by Agentic AI from core components to practical implementation. Whether you’re a developer or a decision-maker, you’ll gain the technical know-how and real-world context to build smarter, faster, and more adaptive AI systems.
What is a RAG system and why does it matter?
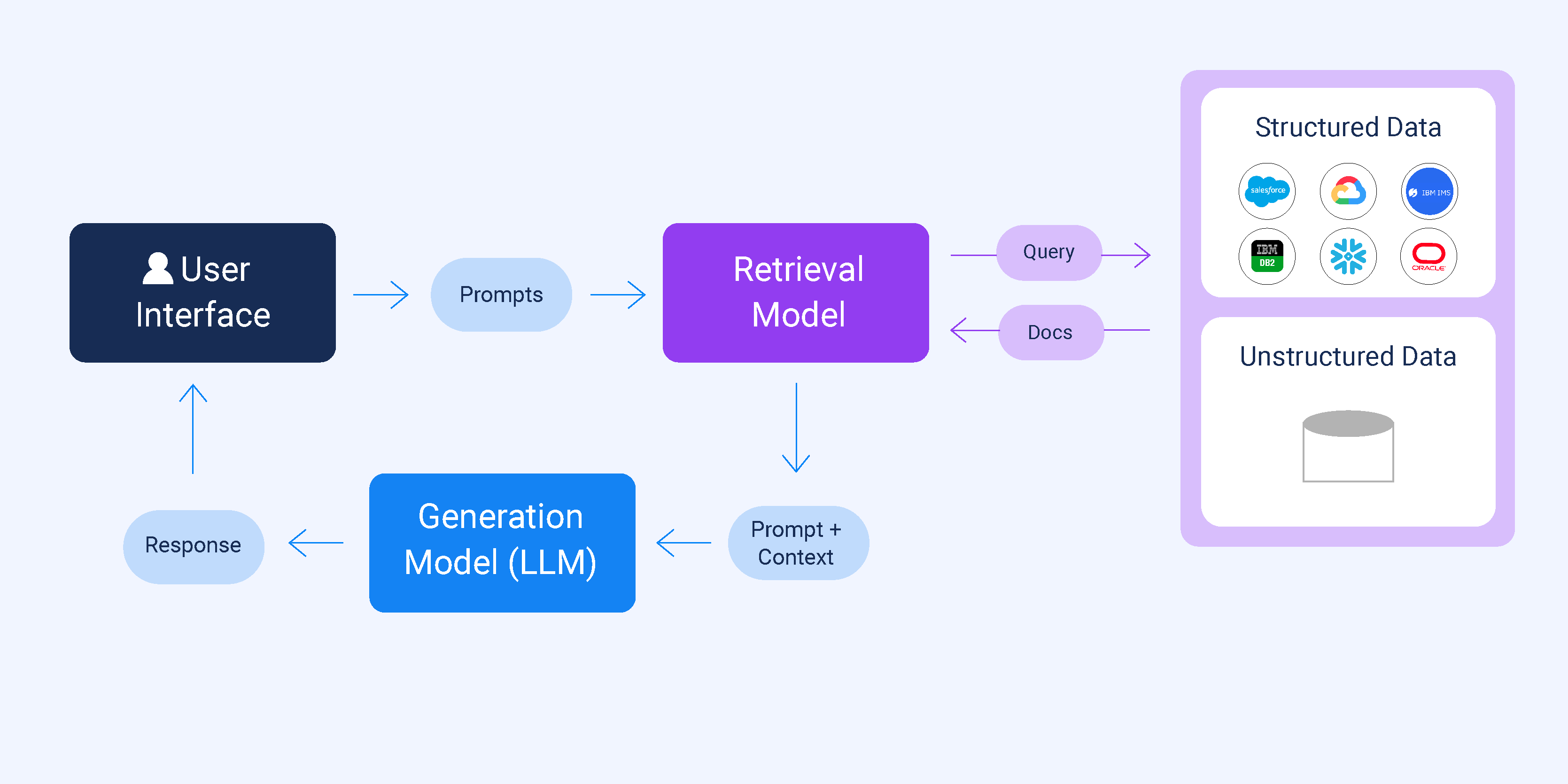
RAG, or Retrieval-Augmented Generation, is an architecture designed to bridge one of the biggest gaps in large language models (LLMs): access to relevant, real-time, and domain-specific information.
While LLMs have made huge strides in content generation and conversational intelligence, many organizations have realized a hard truth: off-the-shelf AI tools don’t always meet enterprise needs. Why? Because these models are only trained on static datasets available to the provider at the time of training. As a result, they often lack access to up-to-date knowledge, internal company data, or nuanced industry-specific context making their answers impressive, but sometimes irrelevant or even misleading.
This is where RAG steps in.
At its core, a RAG system combines two powerful components:
- Retrieval: an intelligent search mechanism that pulls in relevant documents, data points, or context from external sources or internal knowledge bases in real time.
- Generation: an LLM (like GPT or Claude) that uses this retrieved information to generate rich, context-aware, and factually grounded responses.
Think of RAG as a smart research assistant layered on top of your AI, one that not only speaks well but knows where to look for the right answers before speaking at all.
Why RAG makes a difference
- Factual accuracy: By grounding responses in real-time, retrieved information, RAG systems significantly reduce hallucinations and misinformation.
- Context awareness: Responses are tailored based on specific, often complex, queries that reflect your business data, not just what’s publicly available on the internet.
- Up-to-date knowledge: Whether it’s changes in policy, product updates, or market shifts, RAG ensures your AI is always working with the latest information even if your base model was trained months or years ago.
In short, RAG transforms general-purpose AI into a domain-specific expert, making it more useful, reliable, and impactful especially in enterprise environments where accuracy and relevance are non-negotiable.
Why RAG matters for smarter decision-making
Large Language Models (LLMs) like GPT and Claude are powerful, but they’re not perfect. They generate fluent and convincing text, but sometimes they make things up or rely on outdated knowledge. In high-stakes environments like business strategy, research, or customer support, even a small mistake can lead to missed opportunities or poor decisions.
That’s where Retrieval-Augmented Generation (RAG) steps in and why it’s quickly becoming a must-have for organizations aiming to make smarter, faster, and more accurate decisions.
Filling the gaps left by traditional LLMs
LLMs are trained on static datasets, which means their understanding of the world freezes at a certain point in time. They may not know your latest product release, a new competitor in your space, or updated policies. Worse, they can “hallucinate” producing confident but entirely false information.
RAG system solves this by adding a retrieval layer that pulls live, real-world information from trusted sources whether that’s your internal database, documentation, or a curated set of web pages. The model then uses this information to generate accurate, grounded, and up-to-date responses.
Precision matters in business intelligence
In enterprise settings, precision is everything. Whether you’re analyzing market trends, responding to customer queries, or planning product strategies, decisions must be made based on relevant, factual, and timely data.
With RAG, you’re no longer relying solely on the LLM’s memory. You’re giving it access to your knowledge, tailored to your business context. This means the insights you receive are not only intelligent they’re also aligned with your unique environment, priorities, and goals.
How RAG actually works
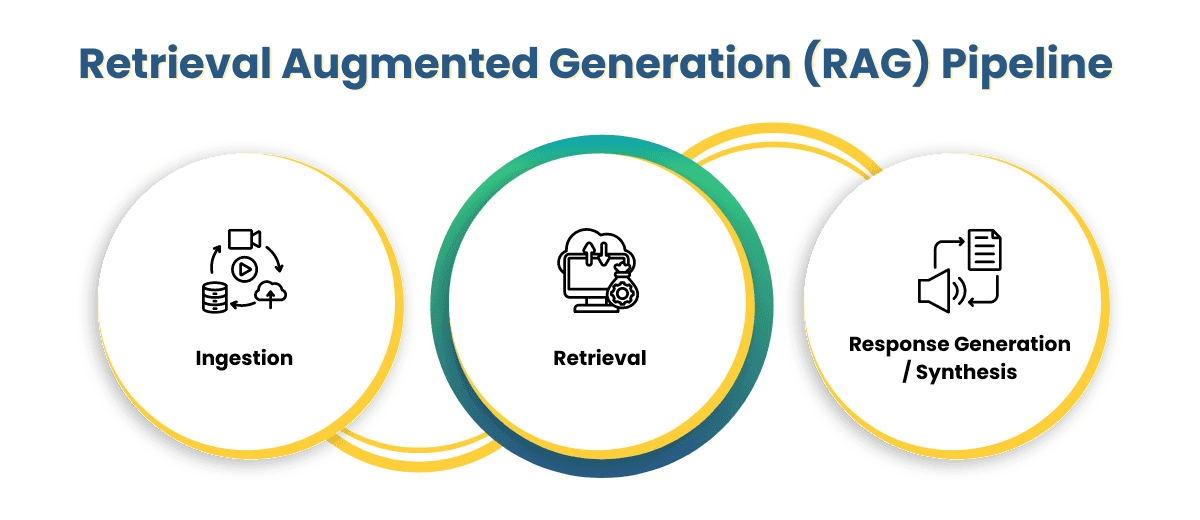
To understand how a RAG system works, think of it like giving a super-intelligent librarian access to your entire digital knowledge base, only this librarian is powered by AI and works in milliseconds.
RAG operates in two key phases: Ingestion and Retrieval, each playing a crucial role in transforming raw data into accurate, real-time, and context-rich responses.
- Ingestion: Building the brain’s memory
The ingestion phase is where the system prepares its knowledge. Imagine loading a massive digital library with documents, articles, manuals, FAQs, and internal reports. But instead of just saving them, RAG uses machine learning to break them down into smaller pieces and convert them into dense vector embeddings, mathematical fingerprints that represent meaning, not just words.
These embeddings are stored in a vector database (like Pinecone, Chroma, or FAISS), allowing the system to later search not by keyword, but by semantic meaning. It’s like organizing a library by ideas, not just titles or topics.
- Dynamic Retrieval & Tool Calling: Finding the right knowledge and right tool, at the right time
When a user submits a question, a modern Agentic RAG system doesn’t just guess based on past training, nor does it execute a simple, one-way keyword search. Instead, it employs Dynamic Reasoning (Chain of Thought). The AI actively breaks down complex queries into smaller, logical steps before searching.
Think of it as the AI librarian scanning the shelves, pulling out the most relevant books and chapters, and ignoring everything that doesn’t fit. However, the 2026 standard introduces Tool Calling (or Routing). If the answer isn’t fully available in the vector database of internal documents, the agent dynamically decides to trigger external tools. It can query your CRM via API for real-time client data, execute an SQL query for live inventory, or run a targeted web search to fill in the gaps.
This multi-hop retrieval step is what separates an active Agentic RAG from standard language models. It ensures that responses are not based solely on static, outdated training data but are grounded in real, context-specific information across all your enterprise systems.
- Generation: Synthesizing a meaningful, accurate answer
Once the relevant information is gathered, the generative model (like GPT or Claude) takes over. But it doesn’t work from scratch, it builds the answer based on the retrieved content, ensuring that what it says is rooted in facts, not fantasy.
The model can:
- Summarize key insights from multiple sources
- Rephrase technical information into human-friendly explanations
- Quote directly from documents
- Combine different pieces of content into a clear, cohesive response
It’s like asking a brilliant librarian to read five reports and explain the most important points in plain English, in just seconds.
The beauty of RAG is that it brings precision and relevance to the power of generative AI. Instead of relying on what the model “remembers,” it enables your AI to consult real knowledge in real time. It answers not just with confidence, but with context which makes all the difference in business, research, and decision-making.
So while traditional LLMs guess, a RAG system searches, verifies, and responds making them far more reliable, accurate, and trustworthy for high-stakes use cases.
Extracting and structuring the right data for RAG system
Every effective RAG system begins with a single, essential task: collecting and preparing the right data. After all, retrieval-augmented generation can only be as smart as the knowledge it pulls from.
In this section, we’ll walk through the full process from intelligently crawling websites to automating the extraction of structured insights using Agentic AI. This is the foundation for building a RAG pipeline that delivers meaningful answers and real-time decision support.
Step 1: Discovering content with BFS crawling
Think of the internet as a massive forest of linked content. To explore it efficiently, we use Breadth-First Search (BFS) , a strategy that helps us navigate from a starting page (like a company homepage) outward to all related subpages, without overwhelming the system or missing critical information.
With BFS, we define a depth limit to control how far the crawler goes and avoid endless loops. As it visits each page, it collects internal links, especially those leading to product pages, integrations, FAQs, or documentation. These links become our roadmap for extracting relevant knowledge.
Step 2: Scraping the right content
Once links are collected, the next step is scraping meaningful content from each page. This includes:
- Page titles
- Product features and capabilities
- Integration details
- Pricing, FAQs, and other structured product data
The scraping logic can be tailored depending on your domain. At the end of this step, we generate a clean JSON file containing URLs and raw content. But raw content alone isn’t enough, we need to make it useful.
Turning raw data into structured knowledge with agentic AI
Now that we’ve gathered the raw material, it’s time to transform it into insights. This is where Agentic AI comes into play acting as an intelligent assistant that reads, understands, and organizes unstructured data into structured formats that RAG system can use.
1. Loading the scraped dataset
We begin by importing the scraped data, typically stored in JSON format, where each entry includes a URL and a text content field. This ensures we’re working with organized input as we move into AI-assisted processing.
2. Extracting valid text
Next, we iterate through the dataset to extract only valid entries. Some pages might be missing content, improperly formatted, or irrelevant. This filtering step helps maintain data quality and model accuracy.
3. Sending content to the AI agent
With the cleaned data in hand, we send the content to the AI agent for processing using prompts to guide extraction. The agent parses the text and returns structured insights, such as:
- Key product features
- Integration options
- Setup instructions
- Troubleshooting guides
This interaction is handled through APIs (e.g., Groq or OpenAI), ensuring fast, repeatable, and consistent results across thousands of documents.
4. Collecting and compiling AI output
The agent may return results in chunks, especially if the original content is large. We collect these fragments, merge them, and format them into a cohesive, organized dataset that’s ready to feed into the RAG pipeline.
Each entry is stored with its source URL, allowing for traceability and confidence in the results.
5. Handling errors gracefully
Not every request will succeed. Some pages may return errors, incomplete data, or trigger rate limits. That’s why we implement error handling logic logging failed entries and ensuring that the pipeline continues without interruption. Entries can be flagged for later review or reprocessing.
6. Saving the final structured dataset
After processing, we save the enriched dataset back into a JSON file now complete with AI-annotated fields. This dataset becomes a critical input for our RAG system, optimized for retrieval and ready to power accurate, context-aware responses.
With the dataset fully processed, we transition into building the RAG pipeline: generating embeddings, setting up vector storage, configuring retrievers, and integrating the language model.
But none of that would be possible without the groundwork laid in this phase collecting, scraping, filtering, and enriching raw content. Without the right knowledge, even the best language model can’t make smart decisions.
This is how raw web content becomes a high-value business asset ready to drive smarter answers, faster decisions, and more intelligent automation.
Scaling with Multi-Agent Systems: The Enterprise RAG architecture
Nowaday, enterprise RAG system is powered by a Multi-Agent Framework—a coordinated team of specialized AI agents working together to ensure precision and prevent hallucinations. Instead of a linear process, this architecture divides the cognitive workload:
- Planner Agent: Acts as the project manager. It analyzes the user’s prompt, breaks down complex business questions, and outlines the exact search strategy needed.
- Search & Routing Agent: Executes the retrieval phase. It intelligently routes queries to the appropriate sources, whether that is a semantic vector database, an external pricing API, or structured SQL tables.
- Validator/Critic Agent: The most critical component for enterprise trust. This agent cross-checks the retrieved data against the initial query. If the data is conflicting or insufficient, it forces the Search Agent to look again. It strictly filters out false information before passing the verified context to the generation model.
By distributing tasks, a multi-agent RAG system processes complex, multi-layered business inquiries with unprecedented accuracy, ensuring that raw web content becomes a high-value business asset.
Which parts of the business can benefit most from the RAG system?

The RAG system is a strategic advantage across the entire organization. By combining real-time data access with the generative power of language models, RAG system can unlock smarter automation, faster workflows, and more accurate decision-making across departments.
From marketing to customer support to internal knowledge management, RAG system helps businesses go beyond generic LLM outputs to deliver
Here are some high-impact areas where RAG system can drive immediate value:
1. Enterprise knowledge management
Imagine every employee having instant access to the right piece of information no more hunting through outdated intranet pages or endless folders.
With a RAG-powered knowledge assistant, employees can ask questions in natural language and receive precise answers pulled from internal documents, wikis, policies, and manuals. Whether it’s onboarding material, technical documentation, or HR policies, RAG system makes internal knowledge searchable, accessible, and usable.
2. Smarter customer service chatbots
Traditional chatbots often rely on hardcoded responses or limited datasets. In contrast, a RAG-enhanced chatbot can dynamically retrieve the latest product details, service policies, and customer-specific data to provide accurate, relevant support instantly.
When a customer asks about a refund policy or product feature, the RAG system searches across knowledge bases, policy documents, and even CRM entries to generate a helpful response. The result? Faster resolution times, fewer escalations, and happier customers.
3. AI-assisted drafting and document creation
Creating reports, emails, or proposals often involves digging through spreadsheets, databases, and documentation to find the right figures or context.
With RAG system, that process becomes faster and smarter. When an employee starts writing, the system can automatically pull in relevant company data like pricing tables, client history, or product specs and prepopulate sections of the document. It’s like having an AI research assistant built into your workflow, helping you work faster, with fewer errors.
Other potential use cases
- Marketing teams: Craft personalized messaging using real-time customer data and brand guidelines.
- Finance departments: Quickly surface historical spending data, compliance policies, or forecasting reports for faster decisions.
- Product teams: Retrieve feedback, feature requests, and usage patterns to guide product development.
Conclusion
Designing a RAG system is a strategic shift in how organizations access, process, and act on information. In a world overwhelmed by data, the ability to connect questions to precise, context-rich answers in real time is no longer a luxury, it’s a necessity.
By combining the speed of intelligent retrieval with the depth of language generation, RAG system bridges the gap between static knowledge and dynamic insight. They enable businesses to extract value from their internal and external data ecosystems, turning scattered information into meaningful, actionable intelligence.
But the true power of RAG system goes beyond technology, it lies in its ability to support better decision-making at every level of the organization. Whether it’s streamlining customer support, accelerating research, empowering product teams, or guiding leadership strategies, a well-architected RAG system becomes a living knowledge engine, always learning, always available, and always relevant.
As your data grows and complexity rises, RAG system gives your business the clarity, agility, and confidence to move faster and smarter.