As the demand for real-time, intelligent AI systems continues to grow, Retrieval-Augmented Generation (RAG) has emerged as a game-changing approach for businesses looking to enhance their AI capabilities. Unlike traditional Large Language Models (LLMs) that rely solely on pre-trained data, RAG dynamically retrieves external knowledge and integrates it into responses, ensuring greater accuracy, relevancy, and contextual depth.
According to the 2023 Retool Report, an impressive 36.2% of enterprise LLM use cases now employ RAG technology. This hybrid approach enables businesses to process vast amounts of information efficiently, making it an essential tool for applications that require current and domain-specific knowledge.
From AI-powered customer service chatbots that deliver precise, real-time responses to automated research assistants capable of pulling the latest industry insights, RAG is reshaping how AI interacts with users. The technology is also driving advancements in personalized recommendations, content generation, and enterprise knowledge management, allowing AI systems to go beyond generic outputs and provide tailored, data-enriched responses.
This blog will delve into the core principles of RAG application development, offering insights into essential tools, best practices, and implementation strategies. Additionally, we’ll explore real-world case studies showcasing how RAG is revolutionizing industries by making AI smarter, faster, and more adaptive to user needs.
Understanding RAG in AI development
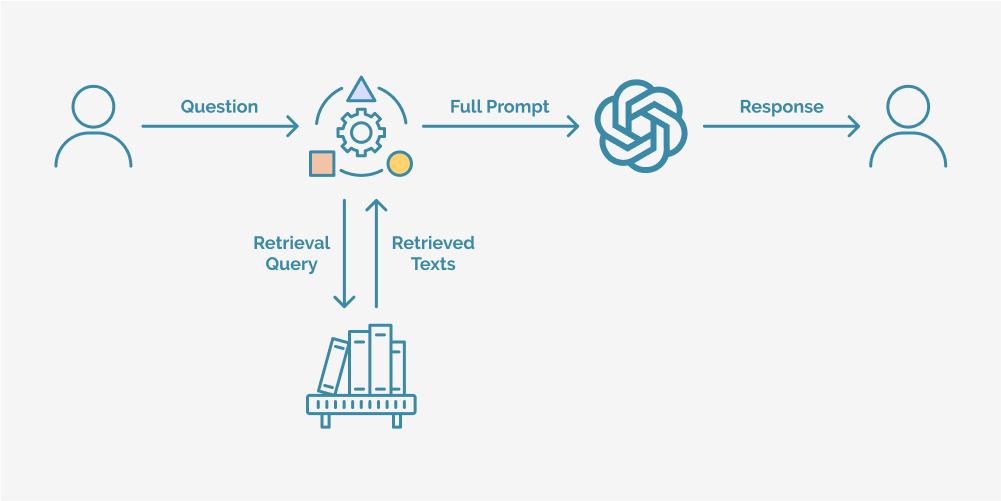
How RAG is revolutionizing AI: A smarter approach to knowledge-driven responses
In the ever-evolving landscape of Artificial Intelligence, the demand for more accurate, context-aware, and real-time responses has driven the development of Retrieval-Augmented Generation. Unlike traditional AI models that operate solely on pre-trained knowledge, RAG enhances AI’s ability to provide fact-based, dynamic, and up-to-date responses by integrating real-time information retrieval into the generation process.
At its core, RAG bridges the gap between static AI models and real-world knowledge by incorporating two key components:
- Retrieval mechanism : Instead of relying only on previously trained data, RAG-equipped AI actively searches external knowledge sources, such as databases, document repositories, or real-time web sources to pull relevant, verified information. This ensures the model stays updated and significantly reduces hallucinations (fabricated or inaccurate responses).
- Context-aware response generation : Once the retrieval process identifies relevant content, the AI model synthesizes this information into a well-structured, meaningful response. By combining retrieval with natural language generation, RAG produces answers that are not just coherent but also factually aligned with real-world data.
Unlike conventional AI models that require frequent retraining to stay relevant, RAG allows AI to continuously adapt by retrieving new information without needing extensive model updates. This makes it highly efficient for industries where accuracy is critical such as legal research, healthcare diagnostics, financial analysis, and enterprise automation.
Why RAG is a game-changer for AI applications
- Reduces misinformation and hallucinations by grounding responses in real-time data.
- Enhances accuracy and credibility, making AI more reliable for professional and high-stakes applications.
- Minimizes the need for constant model retraining, leading to cost-efficient AI maintenance.
- Scales across multiple industries, from customer service to medical and legal AI, where factual precision is essential.
As AI continues to evolve, RAG is setting a new benchmark for intelligent, knowledge-driven systems. By leveraging retrieval mechanisms, AI can provide richer, more insightful, and trustworthy interactions, ensuring that responses remain both relevant and factually sound in an ever-changing world.
How RAG processes queries: A step-by-step breakdown

Understanding the user query
- When a user submits a question, the AI system first analyzes the input, extracting key terms and identifying intent.
- This step ensures that the query is structured properly so the retrieval mechanism can find the most relevant information.
Retrieving relevant information
- The retrieval engine scans databases, documents, APIs, or real-time web sources to locate knowledge that aligns with the query.
- Unlike standard AI models that rely on static knowledge, RAG ensures that responses remain fresh, accurate, and contextually relevant by sourcing up-to-date information.
Generating an intelligent, fact-based response
- Once the most relevant data is retrieved, the language model synthesizes this information, integrating it with its pre-existing knowledge.
- Instead of generating responses based solely on past training, RAG dynamically incorporates retrieved insights, significantly reducing the chances
Delivering a knowledge-rich answer
- The AI system presents a final response that is well-structured, context-aware, and grounded in real-world data.
- This enables AI applications to handle complex, knowledge-intensive tasks with much higher precision.
By integrating retrieval and generation, RAG enables AI to think beyond its pre-existing knowledge, adapting dynamically to new information and delivering responses that are smarter, more reliable, and contextually aware. This innovative approach is setting a new standard for AI intelligence, empowering businesses to build AI solutions that truly understand and respond to complex, data-driven inquiries.
Transforming AI with RAG: Key applications and industry impact
As artificial intelligence continues to evolve, Retrieval-Augmented Generation (RAG) is reshaping how AI applications process and generate information. Unlike conventional Large Language Models (LLMs) that rely solely on pre-trained data, RAG-powered AI dynamically retrieves external knowledge, ensuring more accurate, relevant, and up-to-date responses. This hybrid approach is particularly valuable in scenarios where generative AI alone may struggle with precision and contextual accuracy.

Where RAG is making a difference in AI
- Intelligent Q&A systems
Traditional AI-based question-answering systems often rely on limited, static datasets. RAG enhances these systems by retrieving real-time information from structured and unstructured knowledge bases. This is particularly valuable in fields like medical diagnostics, legal research, and enterprise search, where factual accuracy is critical.
- Advanced chatbots and virtual assistants
RAG is redefining AI-powered assistants by enabling them to retrieve and integrate live data from corporate knowledge bases, regulatory documents, or public sources. Unlike script-based chatbots, RAG-driven virtual assistants can adapt to new information instantly, making them ideal for industries such as customer support, HR, and technical troubleshooting.
- Content summarization and generation
From news aggregation to executive briefings, RAG applications streamline content creation by retrieving core insights and generating concise, fact-driven summaries. Whether used for research papers, legal case summaries, or financial reports, RAG ensures that AI-generated content is contextually accurate and up-to-date.
- Personalized recommendation systems
In sectors like e-commerce, streaming platforms, and digital marketing, personalization is key. RAG enhances recommendation engines by retrieving user-specific data—such as browsing behavior, past interactions, and real-time trends—to create hyper-personalized suggestions, improving user engagement and satisfaction.
- Real-time decision support in healthcare
Medical professionals increasingly rely on AI for diagnostic support and research assistance. RAG-powered AI retrieves the latest clinical studies, treatment guidelines, and patient history, allowing doctors to make data-driven decisions faster. This is particularly useful for rare diseases, drug interactions, and evolving medical protocols.
- Financial market analysis and forecasting
The finance industry thrives on real-time data. RAG optimizes financial analysis by retrieving live market reports, economic indicators, and company earnings data to generate accurate forecasts and investment strategies. This allows analysts to react swiftly to market changes, economic trends, and geopolitical events.
- Smart learning platforms and AI tutors
Educational AI is being transformed by RAG, tailoring lessons, answering complex student queries, and recommending personalized study materials based on retrieved academic resources. This ensures learners receive accurate, diverse, and context-rich educational content.
Key advantages of RAG for AI development

- Increased accuracy and dependability
By incorporating retrieval mechanisms, RAG ensures that AI-generated responses are based on verified, real-world information rather than assumptions. This is especially critical in high-stakes industries such as healthcare, finance, and legal services, where precision and factual correctness are paramount.
- Real-time knowledge access
Unlike traditional LLMs that depend on static training datasets, RAG allows AI models to retrieve and integrate up-to-date information at the moment of inference. This capability is invaluable for news reporting, financial forecasting, stock market analysis, and real-time customer support, where the latest data is crucial for decision-making.
- Optimized computational efficiency
RAG models efficiently allocate resources by retrieving existing information instead of generating content from scratch, significantly reducing computational costs. This makes RAG an attractive solution for businesses looking to scale AI applications without incurring excessive infrastructure expenses.
- Enhanced personalization and user engagement
RAG-powered AI applications can adapt responses based on user preferences, historical interactions, or contextual needs, enabling a more personalized and meaningful user experience. This is particularly useful in areas like customer service, virtual assistants, and recommendation engines, where customization improves engagement and satisfaction.
- Scalable AI solutions for multiple use cases
RAG’s versatility allows it to be applied across a broad range of industries, from automated content creation and intelligent tutoring systems to enterprise search and knowledge management. Businesses can leverage RAG to build AI solutions that evolve with their operational demands without requiring frequent retraining.
- Better performance in low-resource environments
Since RAG models rely on retrieving data instead of storing vast amounts of knowledge in parameters, they require less computational power compared to fully generative models. This makes RAG an ideal choice for businesses with limited processing capacity or for deploying AI in environments with resource constraints.
- Reduced hallucination and improved response credibility
Traditional generative AI models sometimes fabricate inaccurate or misleading responses, a phenomenon known as AI hallucination. RAG minimizes this risk by grounding its outputs in retrieved factual information, ensuring that responses remain credible, verifiable, and aligned with actual knowledge sources.
By combining retrieval and generation, RAG is revolutionizing AI applications, enabling businesses to deploy smarter, more reliable, and cost-efficient AI systems.
Developing a RAG application: A comprehensive guide
Building a Retrieval-Augmented Generation application requires a structured approach that integrates data retrieval with advanced language generation. By carefully designing both components, developers can create AI systems capable of providing accurate, context-aware, and real-time responses. This guide outlines the key steps involved in developing a fully functional RAG application, from initial setup to deployment.
Setting up the development environment
A well-structured development environment is essential for building and scaling a RAG system. The first step is selecting the right machine learning framework, such as PyTorch or TensorFlow, and installing the necessary natural language processing (NLP) and retrieval libraries. For retrieval, tools like FAISS, Elasticsearch, or Pinecone are commonly used, while Hugging Face Transformers provides a robust framework for integrating large language models (LLMs).
Setting up a Python virtual environment is recommended to manage dependencies efficiently, ensuring compatibility across various libraries. This initial setup lays the foundation for building an AI system that can seamlessly retrieve and generate relevant responses.
Data preparation and structuring
The effectiveness of a RAG application depends heavily on the quality and structure of the data used for retrieval. Data preparation involves several key steps:
- Collecting and cleaning data: Gathering relevant textual data from structured and unstructured sources, including documents, articles, and knowledge bases. Cleaning the data involves removing inconsistencies, duplicates, and irrelevant content.
- Indexing for efficient retrieval: Organizing the data using a vector database to ensure fast and relevant retrieval. FAISS and Elasticsearch are widely used for indexing and searching large-scale datasets.
- Tokenizing and embedding: Converting text data into a format compatible with NLP models, typically using BERT, Sentence Transformers, or OpenAI Embeddings. These embeddings help in representing textual data in a way that allows for efficient similarity searches.
A well-prepared dataset ensures that the retrieval system can fetch the most relevant and contextually appropriate information for subsequent text generation.
Implementing the retrieval system
The retrieval component is at the core of a RAG system, enabling AI models to access relevant knowledge dynamically. This step involves creating a vector-based search mechanism that efficiently fetches data in response to user queries.
- Building a Vector Store: This involves transforming textual data into vector embeddings using pre-trained models and storing them in a scalable database.
- Configuring the Search Algorithm: Implementing nearest-neighbor search techniques to quickly find relevant documents based on user input. FAISS, Pinecone, and Elasticsearch provide robust solutions for fast and accurate retrieval.
- Optimizing for Speed and Accuracy: Fine-tuning retrieval parameters to balance speed with precision, ensuring minimal latency while maintaining high retrieval accuracy.
By effectively designing this component, the system ensures that only the most relevant and up-to-date information is passed to the generation model, improving the overall response quality.
Integrating the language generation model
Once the retrieval system is in place, the next step is integrating a large language model (LLM) to generate meaningful and contextually appropriate responses. This requires selecting a pre-trained model such as GPT-4, LLaMA, or T5, depending on the use case.
- Fine-Tuning the model (If Necessary): For domain-specific applications, fine-tuning the LLM on specialized datasets can enhance response accuracy and contextual relevance.
- Integrating retrieval with generation: The retrieved documents are processed alongside the user query to generate responses that are both factually correct and linguistically coherent.
- Enhancing response quality: Techniques such as prompt engineering and context window optimization help refine the interaction between retrieval and generation, reducing errors and inconsistencies.
This step ensures that the model not only generates fluent text but also leverages retrieved data to provide informed and reliable answers.
Testing and evaluation
Comprehensive testing is critical to ensuring the accuracy, efficiency, and reliability of a RAG application. Evaluation methods focus on both retrieval quality and the coherence of generated responses.
- Assessing retrieval performance: Metrics such as Precision@K and Mean Reciprocal Rank (MRR) measure how accurately the system retrieves relevant information.
- Evaluating generation quality: Scores like ROUGE, BLEU, and BERTScore, along with human evaluation, help determine the coherence, factual accuracy, and fluency of the model’s responses.
- End-to-End system testing: Simulating real-world queries ensures that the retrieval and generation components work seamlessly together under different scenarios.
By iterating on these evaluations, developers can refine the system and eliminate potential errors before deployment.
Deploying and scaling the RAG application
Deploying a RAG system requires careful consideration of scalability, cost efficiency, and performance optimization.
- Selecting a cloud platform: Services like AWS, Google Cloud, and Azure provide scalable infrastructure for hosting AI applications.
- Using API-based deployment: Implementing REST or GraphQL APIs allows for easy integration with external applications and services.
- Load balancing and auto-scaling: Setting up automated scaling mechanisms ensures that the system can handle varying levels of traffic efficiently.
- Optimizing for latency and cost: Techniques such as response caching, model pruning, and batch processing help reduce computational overhead while maintaining system performance.
Proper deployment strategies ensure that the application remains responsive, cost-effective, and adaptable to future improvements.
Developing a Retrieval-Augmented Generation (RAG) application involves a combination of cutting-edge retrieval techniques and advanced language modeling to create AI systems that are context-aware, highly accurate, and scalable. By carefully structuring the development process from setting up the environment and preparing data to deploying a robust and scalable solution businesses can harness the power of RAG to build AI applications that deliver real-time, reliable, and intelligent responses.
As the demand for fact-based, dynamic AI systems continues to grow, RAG represents a significant leap forward in AI development, allowing organizations to bridge the gap between knowledge retrieval and natural language understanding.
Conclusion
As artificial intelligence continues to evolve, Retrieval-Augmented Generation is proving to be a game-changer in how AI systems access, process, and generate information. By integrating real-time retrieval with powerful language models, RAG allows AI applications to deliver more accurate, contextually relevant, and up-to-date responses a significant step forward from traditional generative AI models that rely solely on pre-trained knowledge.
Developing a RAG-based application requires careful planning, from choosing the right infrastructure and data sources to optimizing retrieval mechanisms and fine-tuning language models. When executed effectively, RAG enables businesses to build AI solutions that are more intelligent, scalable, and adaptable to real-world demands.
As industries increasingly rely on AI for decision-making, automation, and user engagement, RAG offers a practical and efficient way to enhance AI’s ability to interact with dynamic information sources. Whether in customer support, finance, healthcare, or content generation, businesses that adopt RAG will be better positioned to provide AI-driven solutions that are smarter, more reliable, and more responsive to users’ needs.
Looking ahead, RAG’s role in AI development will only grow, making it an essential approach for organizations seeking to maximize the potential of large language models while ensuring accuracy and real-time adaptability. Now is the time to embrace this next evolution in AI and harness the power of RAG to create AI-driven applications that truly understand and respond to the complexities of the modern world.