In the ever-evolving landscape of artificial intelligence, Google just made another bold move expanding access to the image generation capabilities of its Gemini 2.0 Flash model. If you’ve been watching the AI race unfold, you’ll know this is more than just a technical update, it’s a signal that Google is ready to compete head-on in the generative creativity space.
So, what makes this expansion exciting? For starters, Gemini 2.0 Flash is engineered for speed and efficiency, making it ideal for real-time applications like content generation, visual storytelling, and on-the-fly creative ideation. Now that Google is opening the gates wider, more creators, developers, and marketers have a powerful new tool at their fingertips, a way to instantly bring visual concepts to life, powered by one of the world’s leading AI ecosystems.
Imagine crafting product mockups, campaign visuals, or entire brand aesthetics with just a few lines of input. For content creators, it means faster production with less overhead. For AI developers, it’s an opportunity to integrate world-class generative capabilities into apps and platforms. And for digital marketers, it’s a game-changer making personalized, visually compelling content generation scalable like never before.
This update isn’t just about adding a feature, it’s about democratizing creativity and making AI-generated imagery accessible to more hands and more ideas.
What is Gemini 2.0 Flash?

In the rapidly advancing realm of artificial intelligence, Google’s Gemini 2.0 Flash emerges as a standout model, meticulously engineered to deliver swift and efficient performance across a multitude of tasks.
Introduced in December 2024, this model has swiftly become an indispensable tool for developers and businesses aiming to integrate high-speed AI capabilities into their applications.
Key features of Gemini 2.0 Flash:
- Low latency: Designed for tasks requiring real-time responsiveness, ensuring minimal delays.
- Enhanced performance: Optimized to handle high-volume, high-frequency tasks with remarkable efficiency.
- Multimodal input: Capable of processing diverse data types, including text, images, video, and audio, making it versatile for various applications.
- Extensive context window: Supports a context window of up to 1 million tokens, allowing it to comprehend and generate lengthy and complex content seamlessly.
Position within Google’s AI ecosystem:
Gemini 2.0 Flash is a pivotal component of Google’s broader AI strategy, complementing other models in the Gemini family:
- Gemini 2.0 Pro: Tailored for complex coding tasks and intricate problem-solving, offering advanced reasoning capabilities.
- Gemini 2.0 Flash-Lite: A cost-efficient variant optimized for scenarios where resource conservation is paramount without significant compromise on performance.
While Gemini 2.0 Pro excels in handling sophisticated tasks that demand deep computational resources, Gemini 2.0 Flash is engineered for scenarios where speed and efficiency are critical, making it ideal for real-time applications and high-frequency task execution.
Launch timeline and intended use cases:
Unveiled in December 2024, Gemini 2.0 Flash was introduced to address the growing need for rapid and efficient AI models capable of managing everyday tasks with minimal latency. Its design caters to a broad spectrum of applications, including:
- Real-time data processing: Enabling instant analysis and response in dynamic environments.
- Conversational AI: Powering chatbots and virtual assistants that require quick and contextually relevant interactions.
- Content generation: Assisting in the creation of text, images, and other media forms swiftly and coherently.
- Interactive applications: Enhancing user experiences in gaming, education, and other interactive platforms by providing immediate feedback and content adaptation.
By focusing on low latency and high efficiency, Gemini 2.0 Flash empowers developers and businesses to build applications that demand rapid AI responses without sacrificing quality or depth.
New features: Expanded image generation
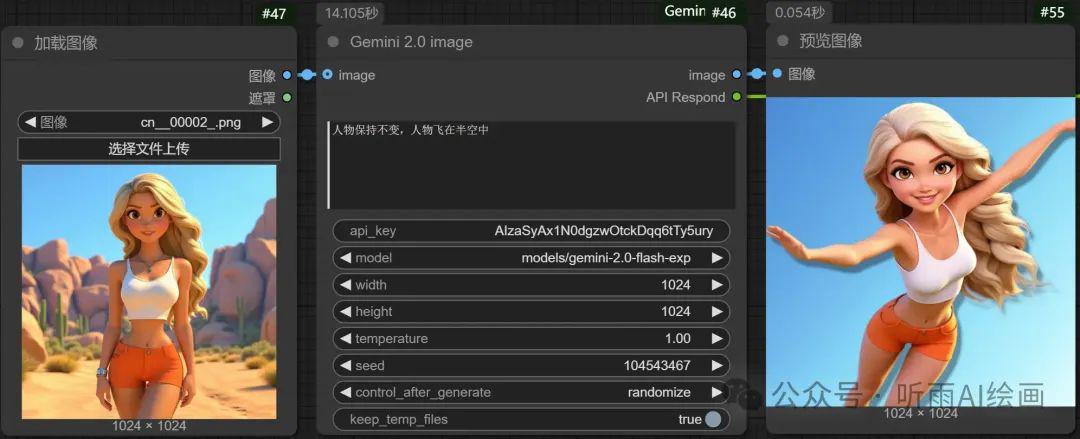
Google’s Gemini 2.0 Flash has recently unlocked a suite of native image generation capabilities, marking a significant advancement in AI-driven creativity.
This enhancement empowers users to generate and edit images seamlessly within the model, streamlining workflows for developers and content creators alike.
Key features of the expanded image generation:
- Integrated text and image outputs: Gemini 2.0 Flash can produce cohesive narratives interwoven with illustrative visuals, maintaining consistency in characters and settings throughout the content.
- Conversational image editing: Users can engage in dynamic dialogues with the model to iteratively refine images, facilitating a more interactive and intuitive editing process.
- Enhanced world understanding: Leveraging extensive knowledge, the model generates contextually accurate and detailed images, such as realistic depictions of recipes or intricate designs.
- Improved text rendering: Addressing a common challenge in AI image generation, Gemini 2.0 Flash excels in accurately rendering text within images, making it ideal for creating advertisements, social media posts, and invitations.
Advancements over previous versions:
Earlier iterations of Gemini focused primarily on text-based tasks with limited image generation capabilities. The introduction of native image output in Gemini 2.0 Flash represents a significant leap, enabling the model to handle multimodal inputs and outputs more effectively. This evolution allows for more integrated and versatile applications, bridging the gap between textual and visual content creation.
Comparison with other AI models:
- Midjourney: Renowned for producing highly artistic and stylized images, Midjourney offers users the ability to create unique visuals through descriptive prompts. However, it may require more detailed input to achieve specific results.
- DALL·E 3: Developed by OpenAI, DALL·E 3 specializes in generating creative and diverse images from textual descriptions. It excels in producing imaginative visuals but may have limitations in text rendering within images.
- Adobe Firefly: Integrated within Adobe’s Creative Cloud suite, Firefly provides tools for generating images with various styles and effects. It offers a user-friendly interface with predefined options, catering to designers seeking quick and customizable visuals.
Gemini 2.0 Flash distinguishes itself by combining rapid image generation with advanced reasoning capabilities, facilitating the creation of contextually accurate and detailed visuals. Its proficiency in text rendering within images further enhances its utility for applications requiring precise textual elements.
Practical applications and demonstrations:
Developers can experiment with Gemini 2.0 Flash’s image generation features through the Gemini API in Google AI Studio. This access allows for the creation of interactive stories, dynamic visual content, and innovative applications that leverage the model’s multimodal capabilities.
For a visual demonstration of Gemini 2.0 Flash’s image generation and editing capabilities, you can refer to the following video:
Where and how to access it
With Google unlocking the image generation capabilities of Gemini 2.0 Flash, a big question naturally follows: Who can actually use this powerful new tool and how?
Unlike many flashy AI announcements that feel out of reach, Google has made it relatively straightforward (at least for now) to get hands-on with this experimental feature. However, it’s still in a controlled rollout phase, meaning full public access isn’t quite here yet but developers and early adopters already have a seat at the table.
Who has access right now?
Currently, the image generation feature is available to:
- Developers and early testers via Google AI Studio
- Organizations using Vertex AI on Google Cloud
- Those experimenting with the Gemini API, specifically under the “experimental” model selection
That means if you’re a developer, AI enthusiast, or someone with a Google Cloud project, you can already start playing with Gemini’s image generation skills. General public access (like on the Google mobile app or Search Generative Experience) hasn’t rolled out yet but based on Google’s roadmap, it’s on the horizon.
Supported platforms
Gemini 2.0 Flash’s image generation is currently supported on two key platforms:
- Google AI studio
This is the fastest way to try Gemini’s capabilities in a friendly, no-code-required environment. You just log in, pick your model, and start chatting or in this case, creating. - Vertex AI (Google cloud)
For developers and businesses building production-level apps, Vertex AI allows you to call the Gemini 2.0 Flash model through an API and integrate image generation into larger workflows or customer-facing apps.
Step-by-step guide to access and utilize the image generation feature
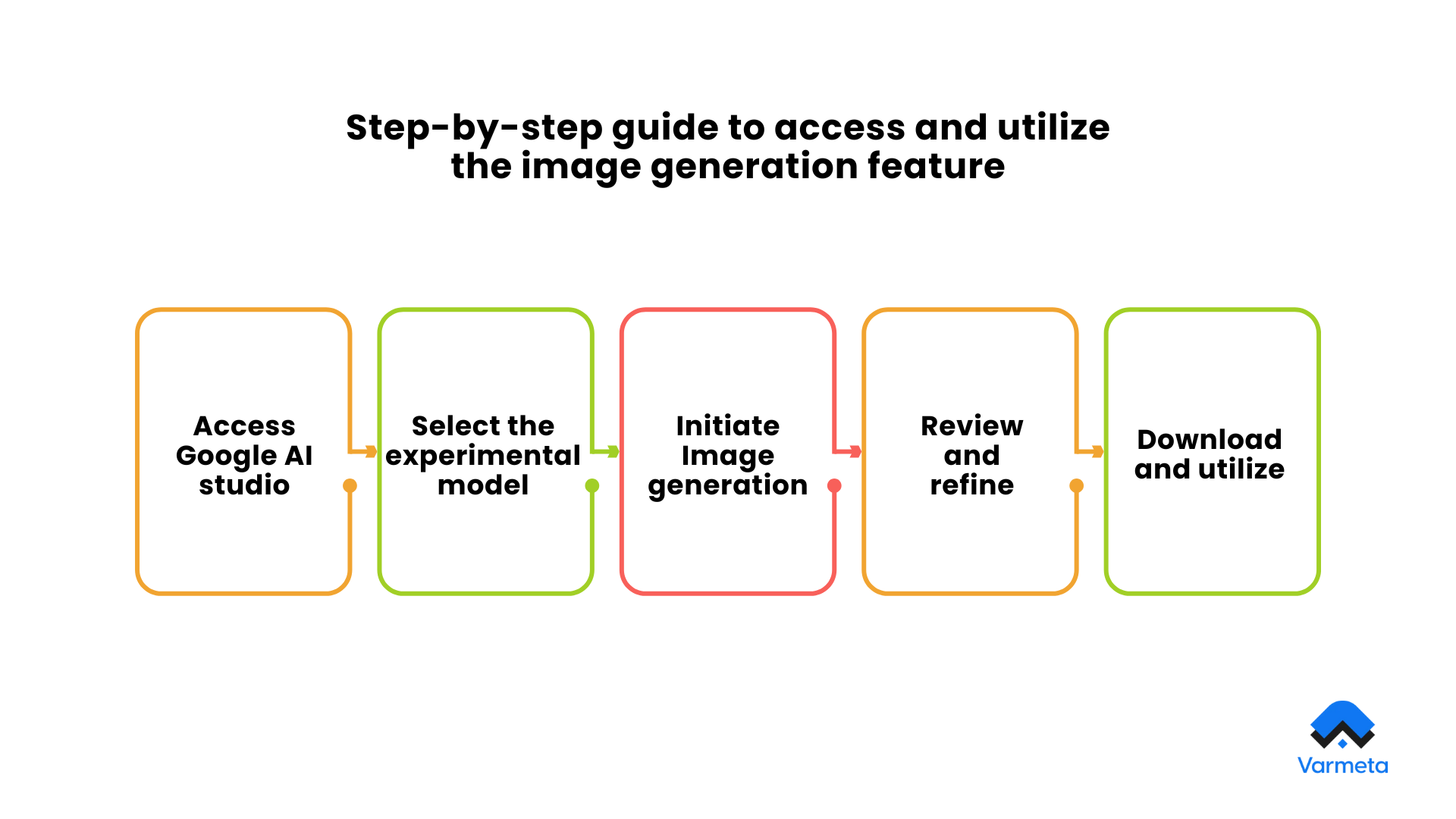
1. Access Google AI studio
- Navigate to Google AI studio
- Sign in with your Google account.
2. Select the experimental model
- Within the AI Studio interface, locate the Run Settings panel on the right-hand side.
- Under the Model dropdown menu, choose Gemini 2.0 Flash Experimental.
3. Initiate Image generation
- In the text input area at the bottom of the page, enter a descriptive prompt for the image you wish to generate.
- Begin your prompt with phrases like “Create an image of…” or “Generate a picture depicting..” to ensure clarity.
- For example: “Create an image of a serene mountain landscape during sunrise.”
4. Review and refine
- After submission, the model will generate the image based on your prompt.
- If the result requires adjustments, you can engage in a conversational manner with the model to refine the image. For instance: “Please make the sky more vibrant” or “Add a river flowing through the valley.”
5. Download and utilize
- Once satisfied with the generated image, you can download it for your projects or further editing.
By following these steps, developers can effectively explore and utilize the image generation capabilities of Gemini 2.0 Flash, paving the way for innovative applications in AI-driven visual content creation.
Use cases and potential applications
With the rollout of image generation in Gemini 2.0 Flash, Google isn’t just flexing its technical muscles, it’s redefining how we create, communicate, and imagine. The potential applications stretch far beyond simple AI experimentation. We’re talking about a powerful creative assistant that fits naturally into the daily workflows of content creators, businesses, educators, and even game developers.
Here’s a closer look at the real-world magic this model can unlock:
Content creation and digital marketing
For content creators, bloggers, and marketers, visual assets are essential for engagement. Gemini 2.0 Flash enables the generation of custom, high-quality images in seconds, aligning seamlessly with written content or campaign messaging. This dramatically reduces reliance on stock photography or external design resources.
Professionals can now:
- Generate tailored visuals to accompany blog articles, thought leadership pieces, and newsletters
- Create unique, brand-aligned images for social media platforms
- Produce campaign visuals that reflect seasonal or event-based themes
By enabling a conversational workflow, Gemini 2.0 Flash also allows marketers to refine visual assets in real time, making content production faster, more flexible, and more consistent.
E-commerce and product presentation
In the e-commerce sector, product imagery plays a critical role in influencing consumer behavior. Gemini 2.0 Flash allows retailers and product designers to create compelling visuals without the time and cost associated with traditional photo shoots.
Practical applications include:
- Crafting lifestyle and context-driven product mockups
- Visualizing product variants in different environments or color palettes
- Designing advertising assets and promotional materials that can be adjusted quickly for A/B testing
This level of efficiency and customization supports faster product launches and more agile marketing strategies.
Education, storytelling, and interactive media
The educational and creative industries stand to benefit significantly from generative AI’s ability to transform ideas into visuals.
In academic contexts:
- Teachers can develop custom diagrams, illustrations, or conceptual images to support lessons
- Students can enhance their projects with visuals that reinforce learning objectives
- Educational platforms can automate content creation to deliver more personalized experiences
For storytellers and creative professionals:
- Authors and screenwriters can visualize characters, settings, or scenes to guide world-building
- Artists and designers can quickly prototype visual concepts or mood boards
- Game developers can produce environmental or character sketches to accelerate the creative process
Integration into digital products and applications
Beyond individual use, Gemini 2.0 Flash can be integrated into digital tools through the Gemini API. This opens up the possibility of:
- Building content management systems that automatically suggest or generate images based on written input
- Enhancing education platforms with dynamic visual explanations
- Powering creative assistance tools within design or writing applications
These integrations position Gemini 2.0 Flash as not just a tool for visual generation, but as a foundational technology for building intelligent, content-aware applications.
In essence, Gemini 2.0 Flash enables a new level of speed and adaptability in visual content creation. By reducing the barriers to high-quality imagery, it allows professionals across industries to work more efficiently, innovate faster, and communicate more effectively. As this technology becomes more accessible, its real-world impact is poised to grow exponentially.
What this means for the AI industry
Google’s recent enhancement of its Gemini 2.0 Flash model to include native image generation marks a pivotal moment in the artificial intelligence landscape. This strategic development not only showcases Google’s commitment to advancing multimodal AI capabilities but also positions the company more competitively against industry counterparts such as OpenAI and Meta.
Strategic positioning in the AI landscape
By integrating image generation directly into Gemini 2.0 Flash, Google has expanded the model’s versatility, enabling it to produce text and images seamlessly. This advancement places Google in direct competition with models like OpenAI’s GPT-4o. As noted by industry observers, Google’s swift rollout of these features allows it to lead in multimodal AI deployment.
Market implications and developer engagement
The introduction of native image generation has garnered significant attention from developers and AI enthusiasts. Early adopters have highlighted the model’s flexibility in iterative design and creative storytelling.
This development also has substantial market implications. For enterprises, the ability to generate and edit images natively within an AI model can streamline workflows in design, marketing, and content creation, potentially reducing reliance on external tools and resources. Moreover, it opens new avenues for AI integration into various applications, enhancing user experiences and operational efficiency.
Insights from industry analysts
Industry analysts view this move as a significant step in Google’s AI strategy. The Financial Times reported that Google’s efforts to regain leadership in AI have boosted investor confidence, with the company’s stock reaching record highs following the announcement of advanced AI models like Gemini 2.0.
In summary, the expansion of Gemini 2.0 Flash’s capabilities underscores Google’s proactive approach in the AI sector, enhancing its competitive stance and offering developers and enterprises innovative tools to advance their creative and operational endeavors.
Conclusion
The expansion of Google’s Gemini 2.0 Flash model into the realm of image generation is more than just another product update, it’s a powerful statement about the future of AI. With native support for creating and refining images directly through conversational prompts, Google has unlocked a new frontier for developers, creators, educators, and businesses alike.
This move signals a shift toward multimodal intelligence that’s fast, accessible, and deeply integrated into the creative process. Whether you’re drafting a blog post, launching an ad campaign, teaching a concept, or prototyping a new product, Gemini 2.0 Flash empowers you to visualize ideas in ways that once required entire teams or expensive tools.
But perhaps what’s most exciting is that this is just the beginning.
As the technology evolves and access broadens, we’ll likely see a surge in how AI-generated visuals are used not just to illustrate, but to ideate, experiment, and communicate with more speed and imagination than ever before.
We encourage you to explore Gemini 2.0 Flash for yourself. Head over to Google AI Studio, try out the image generation features, and see what you can create. Don’t hesitate to share your feedback, your input helps shape the next generation of AI tools.