Artificial intelligence (AI) has transformed the way we interact with technology, especially in natural language processing (NLP). Large Language Models (LLMs) have become incredibly powerful, capable of generating human-like text, answering complex questions, and even assisting in decision-making. However, as AI applications expand, the demand for more efficient, accurate, and adaptable models continues to grow.
Two key approaches to improving LLM performance are Retrieval-Augmented Generation (RAG) and Fine-Tuning. While both methods aim to enhance the quality of AI-generated content, they do so in very different ways. RAG dynamically retrieves external knowledge to generate more informed and contextually relevant responses, whereas fine-tuning involves training a model on specific datasets to improve its performance for specialized tasks.
Recent studies have shown that a well-designed RAG-based architecture can significantly outperform fine-tuned (FN) models across various evaluation metrics. For instance, a simple RAG model has been found to achieve 16% higher ROGUE scores, 15% better BLEU scores, and a 53% improvement in cosine similarity compared to fine-tuned models. These improvements highlight the potential of RAG in generating more accurate and contextually relevant outputs, particularly in scenarios requiring real-time information retrieval.
But what exactly sets these two approaches apart? And how do you decide which one is right for your needs? In this article, we’ll break down the key differences between RAG and fine-tuning, exploring their advantages, limitations, and real-world applications. Whether you’re building an AI-powered chatbot, a knowledge assistant, or a domain-specific language model, understanding these techniques will help you make an informed choice.
Understanding retrieval-augmented generation (RAG)
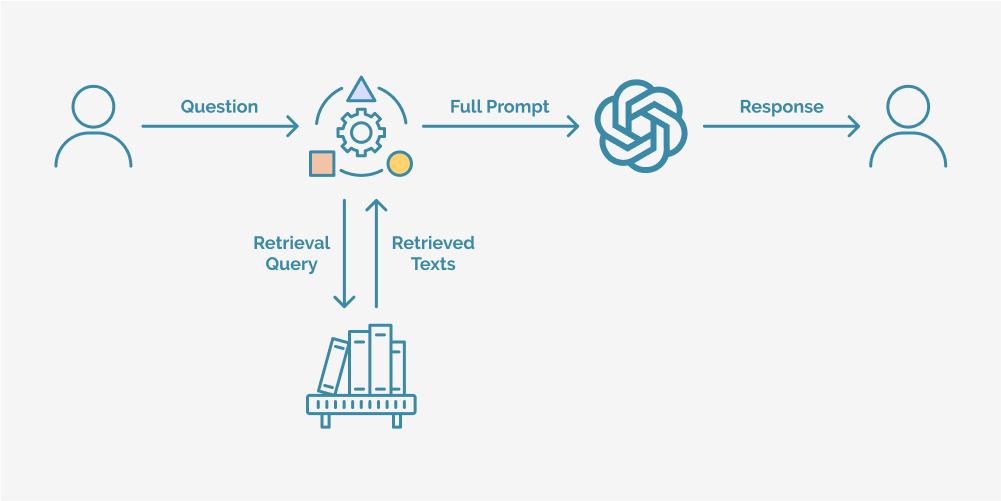
What is RAG?
Retrieval-Augmented Generation (RAG) is an advanced AI technique designed to enhance the quality and relevance of generated responses by retrieving external information in real time. Unlike traditional Large Language Models (LLMs) that rely solely on pre-trained knowledge, RAG dynamically pulls data from external sources such as databases, APIs, or search engines before generating a response. This allows the model to provide more accurate, up-to-date, and contextually rich answers rather than relying on static, outdated training data.
How does RAG work?
RAG operates through a three-step process that ensures responses are both knowledge-rich and contextually relevant:
- Retrieval mechanism
When given a prompt, the model first searches for relevant information from an external database, knowledge graph, or search engine. This could be proprietary data, web-based sources, or structured documents.
- Augmentation with real-time information
The retrieved data is then fed back into the model, enriching its context before it generates a response. This ensures the answer reflects the most current and relevant information available.
- Contextual response generation
The LLM, now augmented with fresh data, processes the prompt and retrieved information together to generate a highly accurate and informed response.
This retrieval-then-generation approach makes RAG particularly effective for scenarios where accuracy, real-time knowledge, and adaptability are crucial, such as customer support, research assistance, or AI-powered search engines.
Advantages of RAG
RAG offers several key benefits that make it a powerful alternative to fine-tuning:
- Access to real-time and dynamic information
Since RAG pulls data from external sources on demand, it can generate responses that reflect the latest developments, eliminating the problem of outdated model knowledge.
- No need for extensive model retraining
Unlike fine-tuning, which requires periodic retraining to incorporate new information, RAG updates itself dynamically through retrieval, saving time and computational resources.
- More efficient use of computational resources
By leveraging external knowledge rather than constantly training on massive datasets, RAG is more scalable and cost-effective for handling a wide range of topics and queries.
Limitations of RAG
While RAG is a powerful approach, it does come with some challenges:
- Dependence on external knowledge bases
The quality of RAG’s responses is only as good as the sources it retrieves information from. If the external data is unreliable, incomplete, or biased, the generated content may reflect those shortcomings.
- Possible latency in retrieval and response generation
Since RAG involves fetching data in real time, there can be a slight delay in response times compared to traditional fine-tuned models, which generate answers directly from pre-existing knowledge.
Despite these limitations, RAG remains a highly effective solution for applications where up-to-date and contextually relevant responses are essential. Its ability to dynamically retrieve and integrate knowledge sets it apart from conventional AI models, making it a valuable tool for search, research, and enterprise AI applications.
Understanding LLM fine-tuning

What is LLM fine-tuning?
Fine-tuning is a process that enhances a pre-trained Large Language Model (LLM) by training it further on specific datasets to improve its performance for particular tasks. While general-purpose LLMs are trained on vast amounts of data from diverse sources, fine-tuning adapts the model to specialize in a specific domain whether it’s legal, medical, financial, or any other field that requires precise, expert-level responses.
By fine-tuning an LLM, businesses and researchers can tailor AI models to their specific needs, making them more accurate, reliable, and effective for specialized applications. Unlike Retrieval-Augmented Generation (RAG), which pulls in external knowledge dynamically, fine-tuning modifies the internal knowledge of the model itself, allowing it to generate contextually relevant responses without relying on real-time data retrieval.
How does fine-tuning work?
Fine-tuning involves retraining a pre-existing LLM using domain-specific or task-specific datasets. The process typically includes the following steps:
- Training with specialized data
The LLM is fed with high-quality, curated datasets that focus on the desired subject area. This could be legal documents, medical research papers, customer service conversations, or proprietary company data.
- Adjusting model parameters
During training, the model learns to prioritize relevant patterns, terminology, and contextual nuances from the new dataset, improving its ability to generate more accurate and industry-specific responses.
- Optimizing performance
After training, the fine-tuned model undergoes evaluation and testing to refine its accuracy and reduce errors. Additional tuning and adjustments may be made to ensure it aligns with real-world use cases.
Advantages of fine-tuning
Fine-tuning is ideal for situations where deep domain expertise and highly specific responses are required. Some of its key benefits include:
- Improved model performance for specialized applications
Fine-tuned models outperform generic LLMs when dealing with industry-specific queries, as they have been trained on more relevant and precise data.
- Ability to generate responses without external retrieval
Unlike RAG, which depends on external knowledge bases, a fine-tuned model relies on its internal knowledge, making it faster and more consistent in generating responses.
- Customization for industry-specific needs
Businesses can tailor fine-tuned models to align with their brand voice, terminology, and operational requirements, improving user experience and reliability.
Limitations of fine-tuning
Despite its advantages, fine-tuning also comes with some challenges:
- Requires significant computational resources
Fine-tuning a large-scale model demands high processing power, memory, and storage, making it an expensive process.
- Potential risk of model overfitting
If the training data is too narrow or biased, the model may overfit, meaning it performs well only on familiar queries but struggles with variations or new scenarios.
- Needs periodic retraining to stay up-to-date
Unlike RAG, which dynamically retrieves the latest information, a fine-tuned model remains static until it is retrained with new data, requiring regular updates to maintain relevance.
While fine-tuning is a powerful tool for creating highly specialized AI models, it is best suited for applications where real-time information is not critical and where deep, contextually relevant knowledge is essential such as legal analysis, financial forecasting, or customer support automation.
Key differences between RAG and LLM Fine-Tuning

The table below outlines the key differences between Retrieval-Augmented Generation (RAG) and Fine-Tuning, helping you determine the best approach for your needs. While both methods aim to enhance Large Language Models (LLMs), they take fundamentally different approaches in how they process, update, and generate information.
|
Aspect |
Retrieval-Augmented Generation (RAG) |
Fine-Tuning |
| Definition | Enhances a pre-trained LLM by dynamically retrieving external knowledge sources before generating responses. | Modifies a pre-trained LLM by training it with labeled datasets, adjusting its parameters for specific tasks. |
| Objective | Ensures responses are contextually relevant and up-to-date by integrating real-time external knowledge. | Optimizes the model’s internal understanding for domain-specific tasks, improving consistency and accuracy. |
| Data Dependency | Depends on an external knowledge base (e.g., vector databases, APIs) to retrieve relevant information dynamically. | Requires a domain-specific labeled dataset for training and validation, embedding knowledge within the model. |
| Training Effort | Minimal, as the core LLM remains unchanged; the focus is on optimizing retrieval strategies. | Requires significant computational resources to fine-tune model parameters using specialized training data. |
| Model Adaptation | Dynamically adapts by retrieving new and relevant external information during inference. | The model remains static after fine-tuning, relying only on its pre-trained knowledge for responses. |
| Knowledge Update | Easy to update by modifying or expanding the external database—no retraining required. | Requires periodic retraining or additional fine-tuning to incorporate new information. |
| Inference Cost | Higher, as the model retrieves information before generating responses, adding computational overhead. | Lower, since responses are generated directly from the fine-tuned model without external retrieval. |
| Examples | LLMs integrated with retrieval systems (e.g., ChatGPT + Pinecone, Elasticsearch). | GPT-3 fine-tuned for contract analysis, customer support, or scientific research. |
Source : Varmeta
Choosing Between Fine-Tuning and RAG: Finding the Right Approach
Deciding whether to use Retrieval-Augmented Generation (RAG) or Fine-Tuning depends on your specific goals, resource availability, and the complexity of your AI application. While RAG is often a flexible and scalable option, these two approaches are not mutually exclusive, they can complement each other to maximize the effectiveness of an AI system.
Key considerations
Each approach comes with its own advantages and challenges:
- Fine-tuning allows for deep customization and improved model accuracy within a specialized domain, but it requires significant computational resources, labeled datasets, and continuous retraining to stay relevant.
- RAG, on the other hand, reduces the need for retraining by dynamically pulling external knowledge. However, it requires an efficient retrieval system and high-quality data sources to maintain reliability.
When to use both RAG and fine-tuning
If resources allow, combining fine-tuning with RAG can yield powerful results. A fine-tuned model can be optimized for a specific domain or task, while RAG can supplement it with the most up-to-date information from external knowledge bases. This hybrid approach ensures both specialization and adaptability, making it particularly useful in areas like legal research, healthcare AI, and financial analysis.
The importance of data quality in AI development
Regardless of which approach you choose, data quality is the backbone of any successful AI model. Both RAG and fine-tuning rely on structured, accurate, and well-maintained data pipelines to function effectively. Ensuring that your data sources are comprehensive, unbiased, and frequently updated is critical to producing reliable AI outputs.
Enhancing AI reliability with data observability
To maintain high-performing AI systems, data observability is essential. This involves implementing automated monitoring solutions that track data integrity, detect inconsistencies, and resolve issues before they affect model performance. A robust observability framework ensures that your AI system whether using RAG, fine-tuning, or both remains trustworthy, scalable, and efficient.
Making the right choice
Ultimately, the decision between RAG and Fine-Tuning should align with your business needs, available resources, and long-term AI strategy. While RAG provides real-time adaptability, fine-tuning delivers deep expertise and in many cases, leveraging both can create a highly optimized AI solution. By prioritizing high-quality data and a clear AI roadmap, you can unlock the full potential of LLM-driven applications.
Conclusion
As AI technology continues to evolve, the decision between Retrieval-Augmented Generation (RAG) and Fine-Tuning comes down to your specific needs and priorities. If you require real-time, dynamically updated information, RAG is the way to go. If your goal is deep customization and specialized expertise, fine-tuning will provide more precise and consistent responses.
That said, these two approaches aren’t mutually exclusive. In many cases, combining fine-tuning with RAG can offer the best of both worlds; fine-tuning ensures domain expertise, while RAG provides access to the most up-to-date information. This hybrid approach is particularly valuable in fields like healthcare, finance, and legal AI, where accuracy and adaptability are equally important.
Looking ahead, AI models are becoming smarter, more efficient, and better at integrating external knowledge. Advances in automated fine-tuning, retrieval optimization, and real-time learning will further enhance how LLMs operate, making AI even more powerful and scalable.
Ultimately, the best approach depends on your specific use case, available resources, and long-term goals. By understanding the strengths and limitations of both RAG and fine-tuning, you can make informed decisions that maximize the potential of AI in your organization.