Large language models are transforming how businesses and developers build intelligent applications across industries. These models enable machines to understand context, generate human-like text, and adapt to diverse use cases. Explore how LLMs can elevate your AI strategy with Varmeta today.
What Are Large Language Models?
Large language models (LLMs) are the core technology behind generative AI. They are able to understand and answer questions naturally since they are trained in a vast collection of textual data. Today, LLMs are widely applied to generate written and visual content, produce summaries, and even write code.
Users communicate with LLMs by providing prompts, questions, and contextual information in natural language. For instance, to request a summary of an article, a user first supplies the article’s text for the model to process and analyze. Then, the user specifies the desired outcome through a prompt. Based on this input, the LLM generates a concise, high-level summary. Generally, models trained on larger and more diverse datasets tend to deliver more accurate and comprehensive results.
When supported by high-quality data, LLMs offer numerous practical applications for businesses. For example, sales teams can leverage AI to automatically generate tailored sales pitches using customer information that reflects individual needs, pain points, and preferences.
Advantages and Disadvantages
| Pros | Cons |
| Adaptability: Built on transformer-based architectures rather than rigid, hard-coded rules, LLMs can effectively handle dynamic, complex, and unpredictable prompts.
Flexibility: There is no single prescribed way to deploy LLMs; organizations can tailor them to function as AI assistants, copilots, or fully autonomous agents. Performance: As LLMs process and learn from increasing volumes of data, their accuracy and responsiveness improve, shortening the time between question and answer. Efficiency: Since much of the learning and operation occurs with minimal human intervention, employees can focus more on higher-value, strategic activities. |
Development and operational costs: Building and maintaining LLMs requires significant time and resources, including coding, testing, data integration, and model validation.
Ethical concerns: Using data without proper consent or relying on biased datasets can lead to legal issues and unfair or skewed outputs. Security risks: Training models on both public and private data increases the risk of data leakage or system compromise. |
How Do LLM Work?
Large language models’ working process involves inference and training. Below is our step-by-step explanation of how LLMs operate.
Step 1: Collecting Data
The first step in training a large language model (LLM) is collecting massive volumes of high-quality text data from diverse sources such as books, articles, websites, and digital publications. A large and well-balanced dataset helps the LLM develop a stronger understanding of language patterns, context, and real-world knowledge, which directly improves the model’s overall accuracy and performance.
Step 2: Tokenizing
After the training data is collected, it is processed through a technique called tokenization. Tokenization breaks text into smaller units known as tokens, which may include words, subwords, or individual characters, depending on the model and language. This step enables large language models (LLMs) to analyze text at a detailed level, improving their ability to understand meaning, context, and linguistic structure.
Step 3: Pre-training
During the pre-training phase, the large language model (LLM) learns from tokenized text data by predicting the next token in a sequence based on the tokens that come before it. This unsupervised learning process enables the model to grasp language patterns, grammar rules, and semantic meaning. Pre-training is commonly built on a transformer-based architecture that uses self-attention mechanisms to identify and model relationships between tokens, forming the foundation for accurate and context-aware language understanding.
Step 4: Transformer Architecture
Large language models (LLMs) are built on the transformer architecture, which consists of multiple layers of self-attention mechanisms. These mechanisms calculate attention scores for each word by analyzing how it relates to other words in the sentence. By assigning different weights to different terms, LLMs can identify and prioritize the most relevant information, enabling more accurate, coherent, and context-aware text generation.
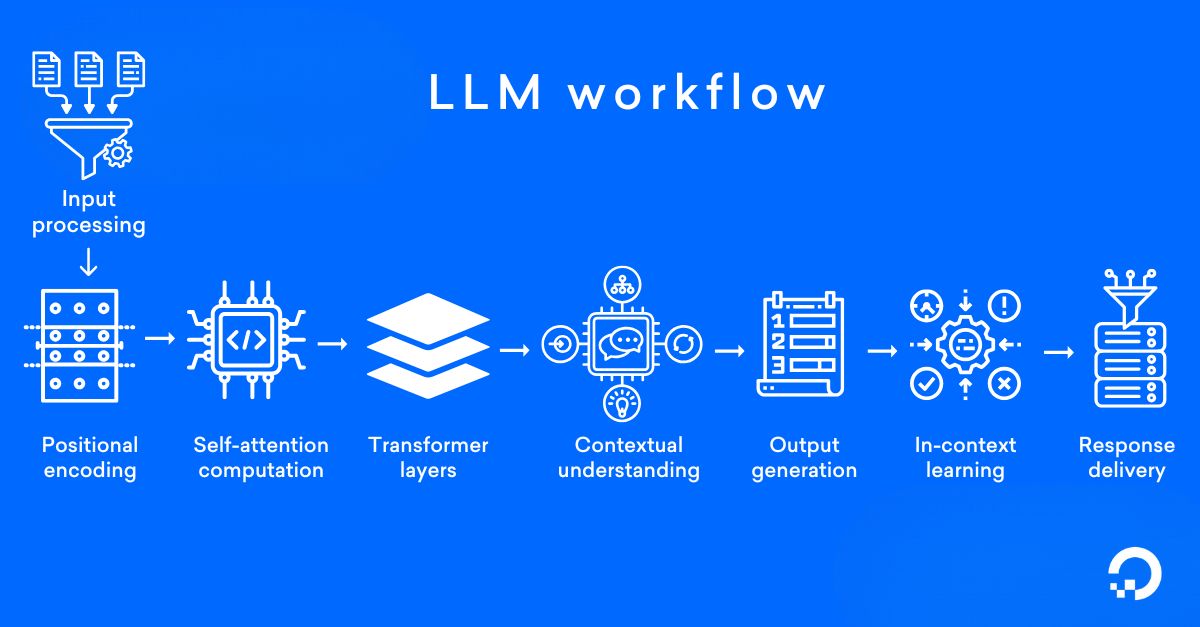
Step 5: Fine-tuning
Following pre-training, a large language model (LLM) is further optimized through a fine-tuning stage focused on particular use cases or industries. In this step, the model is trained with labeled, task-oriented datasets so it can adapt to the unique requirements of each application. As a result, the LLM becomes more proficient in specialized functions such as sentiment detection, question answering, and other domain-specific language tasks.
Step 6: Inference
After a large language model (LLM) has completed training and fine-tuning, it enters the inference stage, where it is applied to real-world tasks. During inference, the model uses its learned knowledge and contextual understanding to generate text, answer questions, or carry out other language-based functions. When provided with a prompt or query, the LLM can produce clear, relevant, and context-aware responses.
Step 7: Understanding Context
Large language models (LLMs) are highly effective at understanding context and producing responses that align with the surrounding information. They analyze the entire input sequence to generate text that reflects prior content and meaning. This capability is powered by self-attention layers within the transformer architecture, which allow LLMs to recognize long-distance relationships between words and maintain strong contextual awareness throughout the text.
Step 8: Beam Search
During the inference stage, LLMs commonly use a method known as beam search to identify the most probable sequence of tokens. Beam search works by evaluating multiple potential generation paths at the same time and selecting the top candidates according to a scoring system. This strategy improves the coherence, fluency, and overall quality of the text produced by the model.
Step 9: Generate Response
Large language models (LLMs) create responses by forecasting the next token in a sequence using both the provided context and the knowledge acquired during training. This process allows the model to produce outputs that are varied, creative, and closely aligned with the intent of the input, resulting in human-like language generation.
In summary, LLMs follow a multi-stage training and deployment pipeline that enables them to recognize linguistic patterns, maintain contextual awareness, and generate natural, high-quality text similar to human communication.
Popular Types Of LLMs
Here are some widely used types of large language models that differ in architecture, training approach, and practical applications.
Autoregressive Models
One of the most popular types of large language models (LLMs) is autoregressive writer models, which generate text sequentially based on user input. Well known examples include GPT from OpenAI, Claude from Anthropic, and LLaMA from Meta. These models function like creative AI writers. When given a prompt, they continue producing text in a fluent and natural way.
Autoregressive LLMs excel at creating human-like content such as blog articles, conversations, stories, programming code, and even poetry. However, because they generate responses by predicting likely word sequences rather than verifying factual accuracy, they may occasionally produce incorrect or invented information. This phenomenon is known as hallucination, so important details should always be checked against reliable sources.
Masked Language Models
Another important category of large language models is known as Masked Language Models (MLMs), with well known examples such as BERT and RoBERTa. Rather than producing text word by word, these models are trained to predict missing tokens within a sentence, similar to completing a language puzzle. This approach helps them build a deep understanding of semantic meaning and contextual relationships, which makes them highly effective for applications like text classification, spam detection, sentiment analysis, and question answering systems.
Compared to GPT style generative models, MLMs are not designed to write long-form content or engage in open-ended conversations. Instead, they specialize in text comprehension and analysis, where they often deliver higher precision and reliability. In their specific use cases, masked language models are usually more lightweight, faster to run, and less susceptible to hallucinations. However, they are not general purpose creators, and therefore are not suitable for tasks such as writing newsletters or blog posts.
General Encoder-Decoder Models
Another group of transformer based models is designed to convert one form of text into another, with notable examples including T5 and MarianMT. These are known as encoder decoder models. They operate through a two stage process in which the encoder processes and interprets the input text, while the decoder produces the corresponding output.
This architecture makes encoder decoder models especially suitable for structured language applications such as machine translation, text summarization, and content rewriting. When compared with other large language model types, they are typically more resource intensive and slower to run. However, they offer greater control and higher accuracy for specific tasks. For use cases that require precise translations or well structured summaries, models like T5 can often deliver better results than general purpose models such as GPT.
Retrieval-augmented Generation Models
A new generation of language models goes beyond relying solely on internal training data by actively retrieving information from external sources. These hybrid AI models integrate tools such as search engines, knowledge bases, or databases to fetch up to date facts while producing responses. This technique is known as retrieval augmented generation (RAG).
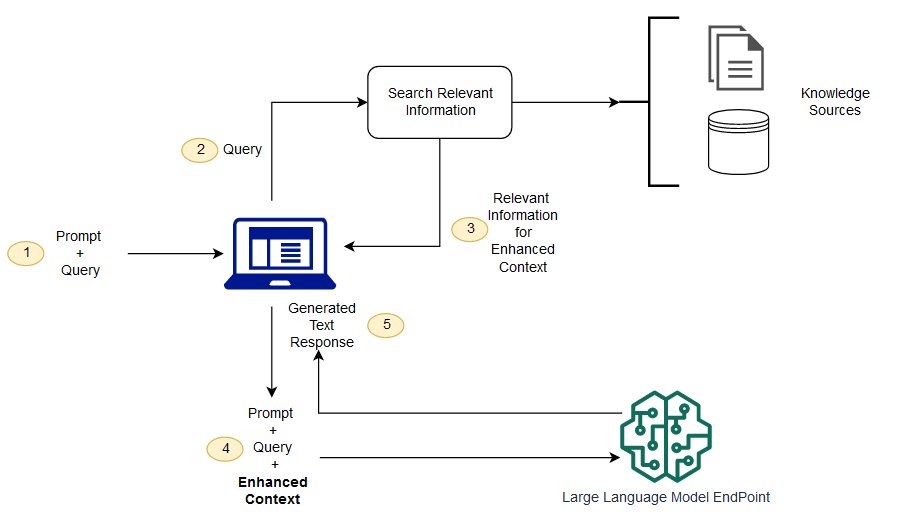
Examples of models that apply this approach include Cohere’s Command R. While RAG based systems can deliver more accurate and information rich outputs, they are typically more complex to develop, require additional infrastructure, and often operate at a slower speed, which can increase overall deployment costs.
Use Cases and Practical Applications of Large Language Models
Large language models are widely applied across industries to automate tasks, enhance productivity, and improve user experiences.
Generating Text
LLMs can create content using your own business data, allowing messages to be more personalized and closely aligned with customer needs. For instance, marketing teams can leverage LLMs to craft compelling calls to action, develop product launch copy, or write targeted promotional emails. Likewise, commerce teams can apply AI powered tools to generate customized offers and promotional content that supports sales growth.
Summarizing Content
Large Language Models (LLMs) allow users to quickly condense lengthy content into clear, concise summaries. In addition, users can tailor the summary format to match their needs, whether as brief paragraphs, bullet-point lists, or one-sentence highlights.
Answering Knowledge Base
Businesses often build centralized knowledge systems to store helpful information for both staff and customers. By connecting to these databases, LLMs are able to retrieve relevant insights and provide precise answers to incoming questions.
Generating Code
After being trained on a particular programming language, Large Language Models (LLMs) can be applied to automate code creation. For instance, development teams may request an LLM to produce Python scripts that execute a defined task.
Analyzing Sentiment
Large Language Models (LLMs) are capable of gathering and processing information from social networks, email communications, messages, and multiple digital channels to evaluate audience sentiment. This approach enables marketing teams to leverage AI-powered sentiment analysis to detect dissatisfied customers early and proactively address their concerns.
Translating Language
Large Language Models (LLMs) can function as AI-powered translation tools, enabling support teams to communicate with customers across multiple languages. These models are able to convert sentences or full paragraphs from one language to another with ease, thanks to the vast volume of digital text they are trained on. However, because nuanced context may sometimes be lost in translation, human review remains essential to ensure accuracy and clarity.
Classifying And Categorizing
With the support of Large Language Models (LLMs), organizations can automate and simplify data classification and tagging workflows. Teams define clear rules such as assigning records with certain attributes or values to specific groups. After that, LLMs scan entire datasets and automatically place matching information into the appropriate categories.
AI Agents
Recent progress in Large Language Models (LLMs) has paved the way for intelligent AI agents. These self operating systems deliver tailored, real time assistance for both customers and internal teams and can be configured to align with unique business needs.
Top Large Language Models in 2026
These leading LLMs in 2026 stand out for their innovation, efficiency, and wide range of practical applications.
GPT Family (Open AI)
The GPT (Generative Pre trained Transformer) series from OpenAI represents a major evolution in generative AI technology. Starting with GPT 1 and its early transformer foundation, each subsequent version has expanded in scale and capability, leading to stronger language understanding and more natural text generation. Newer generations such as GPT 4 further enhance performance by supporting multimodal inputs like text and images while offering more refined fine tuning options.
GPT based language models are widely adopted across many AI driven applications, including conversational chatbots, automated content production, and software development support. Among them, GPT 3 has played a key role in powering virtual assistants, enhancing customer support, and enabling creative writing tasks. The effectiveness of these models is commonly assessed through measures such as text fluency, coherence, and human quality evaluations.
Bert Family (Google)
BERT, a transformer based language model created by Google, is recognized for its ability to analyze text using two directional context. Instead of reading sentences in a single flow, BERT evaluates information from both left to right and right to left, resulting in a more accurate understanding of meaning and intent.
BERT based models and their optimized versions are commonly applied in applications such as search query prediction, text labeling, and semantic encoding. Thanks to their strong contextual understanding, these models are highly effective for enhancing search engine performance, sentiment detection, and other use cases that demand advanced text interpretation.
Gemini
Gemini is a next generation Large Language Model introduced by Google in December 2023. Built on advanced reinforcement learning methods and a novel architectural design, Gemini delivers leading performance across multiple natural language processing benchmarks. This model is engineered to manage complex workflows with stronger contextual awareness and more powerful text generation abilities.
Gemini serves as the latest evolution of Google’s language model ecosystem, building on the foundational technologies of PaLM and the former Bard system. It is particularly well suited for demanding applications such as software development assistance, creative content generation, and advanced conversational AI. By combining reinforcement learning with scalable architecture, Gemini enables more accurate coding support, richer creative writing, and deeper reasoning across diverse tasks.
Relationship Between LLM, Agentic AI And Generative AI)
This section explains how LLMs, Agentic AI, and Generative AI are connected and work together within modern AI systems.
Key Differences
- Generative AI is the broadest concept, covering any AI system that can create original content such as text, images, audio, video, or code.
- Large Language Models (LLMs) are a specialized branch of generative AI that focus on language-based tasks like writing, summarizing, and conversational interaction.
- Agentic AI introduces autonomy, allowing AI systems to plan, make decisions, and execute actions with minimal human involvement.
These three AI approaches work best together. For example, generative AI may produce content, LLMs can refine and structure it, while agentic AI can autonomously distribute, monitor, and optimize outcomes.
How Generative AI, LLMs, and Agentic AI Collaborate?
Agentic AI, Generative AI, and Large Language Models (LLMs) function best when used together, forming an integrated ecosystem rather than separate technologies. Each layer contributes a unique strength within advanced workflows. For example:

- A Generative AI system creates the initial version of a marketing email.
- An LLM adjusts wording, tone, and structure to better align with audience preferences.
- An Agentic AI solution automatically schedules delivery, sends the message, monitors engagement, and optimizes future campaigns.
This combined approach allows organizations to increase efficiency, automate multi-step processes, and make more informed decisions at scale.
Further Vision Of LLMs
From my perspective, the future of Large Language Models is unfolding along two clear directions: scaling up and scaling down. On one hand, advances in deep learning techniques and computing power will continue to push large scale language models to process massive datasets with greater speed and precision.
On the other, I also see strong momentum toward compact language models that deliver comparable performance within smaller, carefully curated data environments. These lightweight models give businesses the flexibility to define highly specific use cases and still achieve accurate, reliable results.
FAQ
Find quick answers to common questions about large language models, their capabilities, and real-world usage.
What Are Common Offline LLMs?
Many well-known open-source large language models are highly regarded for both their strong performance and ease of access:
- Mistral 7B: A high performance language model with seven billion parameters, designed to deliver strong results while maintaining computational efficiency.
- Llama 2: An open source large language model developed by Meta, offered in multiple model scales to suit different use cases.
- Gemma: A collection of open source language models released by Google, optimized for accessibility and broad adoption.
What Hardware Specifications Support Offline LLM Deployment?
Hardware needs differ based on model scale and the level of performance you expect. Below is a practical reference for running LLMs locally:
- Entry Level: At least 8GB of RAM and a reliable multi-core CPU such as Intel Core i5 or AMD Ryzen 5.
- Recommended Setup: 16GB or more RAM combined with a dedicated graphics card like Nvidia RTX 3060 or higher to achieve faster inference speeds.
- Advanced Configuration: 32GB or more RAM paired with a high-performance GPU such as Nvidia RTX 4090 or an equivalent option for intensive workloads.
How Are Large Language Models Trained?
There are three main learning approaches: zero-shot learning, where models answer without prior examples; few-shot learning, which uses a small number of examples to improve accuracy; and fine-tuning, where models are further trained on task-specific data to achieve better performance.
Large language models continue to reshape how businesses and individuals create, analyze, and automate content across industries. As these technologies evolve, they unlock new opportunities for smarter workflows, deeper insights, and more efficient decision-making. Explore more articles on Varmeta to gain deeper knowledge and stay up to date with this rapidly advancing field.